Imagine, dream, create: AI image tools in 2024

For me, one of the most exhilarating forms of generative AI (GenAI) is image generation. These fantastic algorithms, trained on vast collections of digital images scraped from the internet and powered by immense cloud computing data centers, can magically generate almost any type of image you can imagine, eliciting delight and amazement (along with a dash of angst for anyone who up till now earned a living as a commercial artist.)
What was once only possible with years of practice, training, and access to professional gear and expensive art supplies, is now achievable for under $20 a month. To call this technology disruptive is an understatement. To call it miraculous would be reasonable. Our ancestors would certainly think so.
Side-stepping the entire debate about whether or not these tools should even exist given several contentious ethical issues, it’s worth exploring how the leading tools on the market differ and why you might choose one over another for your next creative project.
It's hard to pick just one!

Over the past few months I’ve been testing/trialling/piloting several of the leading image generators. Each has its strengths and weaknesses, and they all do things a little differently. They have also been improving and adding features at a steady pace so it’s been difficult to stick with just one for any length of time. For the purposes of this comparison, I’ll be sharing my thoughts on the following: DALL-E, Leonardo, Stable Diffusion, and Midjourney. I’m not going to review Flux even though it’s been getting a lot of buzz because it just came out and it doesn’t have its own app or UI, and I’m not going to review Meta’s or Google’s tools because by most accounts they’re not very good and I don’t consider them to be professional grade.
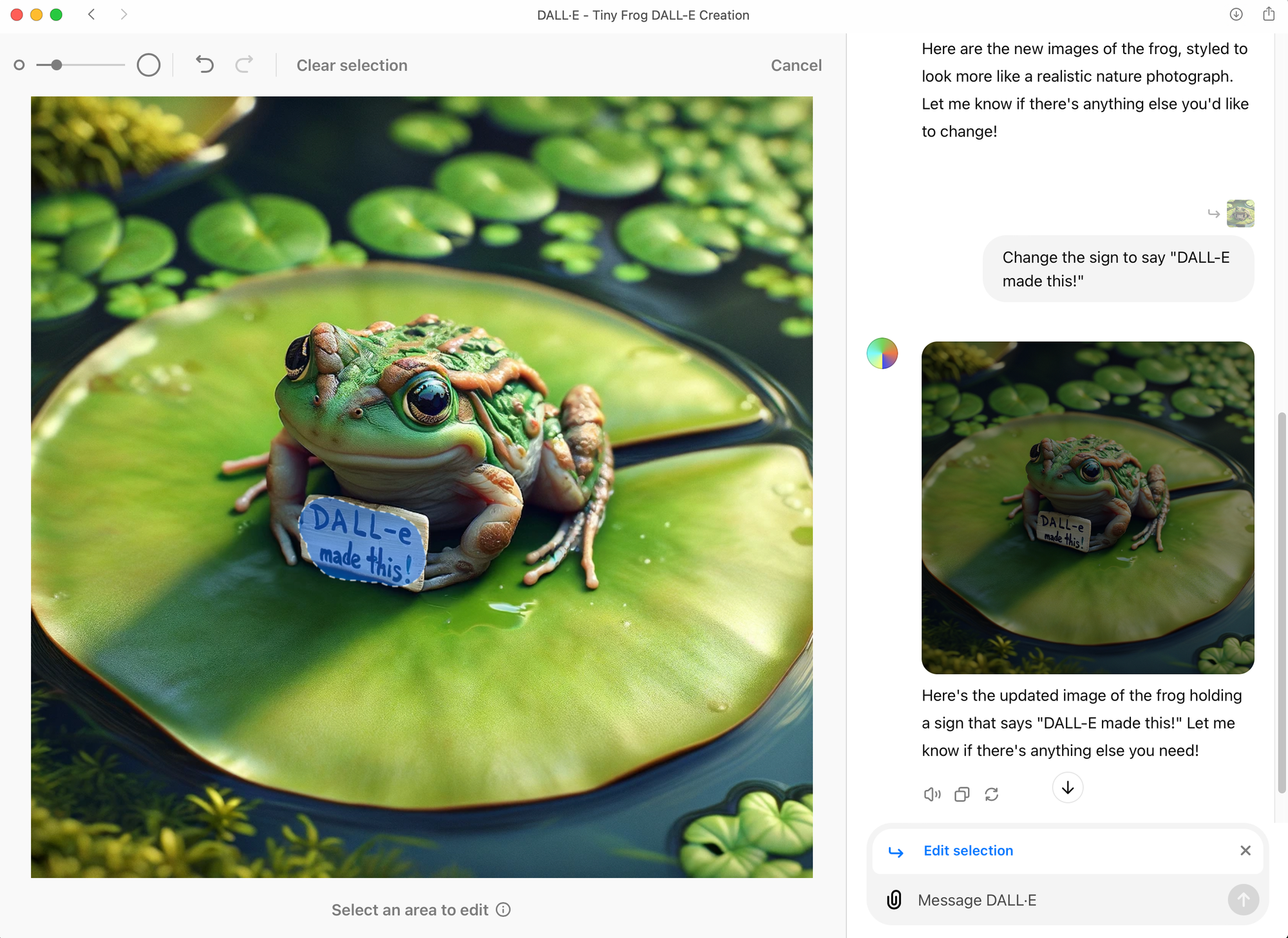
Most of my exploration and experimentation has been driven by a particular need, like generating a hero image for a blog post image. Occasionally though, I’ve just been keen to try out a new model or a new feature, and as a result my output has been a bit all over the map. Eventually I found myself using a fairly simple but flexible prompt so I could compare apples to apples, or in my case, a tiny frog on a lily pad holding up a hand-painted sign that says the name of the tool. I’ll often include some dragonflies and lotus blossoms in the prompt to liven it up a bit, but also to gauge how it handles complexity.
And while many tools currently offer more advanced features and capabilities, such as using a style reference to be able to match a specific image, or the ability to create custom LoRAs to consistently replicate a visual specific style, the focus of my assessment is on their ability to generate great images without having to go to these lengths, through prompting and basic editing. This means I’m primarily looking at prompt adherence, image quality, style flexibility, and the ability to edit or adjust an image using inpainting, or extend an image using outpainting. That said, I’ve listed some of the extra special features these tools offer, where applicable.
And if you’d prefer to skip the in-depth assessments of the different tools, you can scroll down to the summary table I've generated, where I provide a high-level overview of all the tools covered in this article.
Salvadore DALL-E

For many people DALL-E may be the first image generator they try, because it comes bundled with ChatGPT, the most popular AI tool on the planet. And for most people, DALL-E may well be the easiest of the bunch, as it certainly has the lowest barrier to entry. The interface is by far the simplest, being basically chat-driven with a modest number of editing tools. But it’s also one of the most flexible (when it behaves) because you can keep prompting in a back and forth chat till you get something you’re happy with. I say “when it behaves,” because sometimes it doesn’t actual work as expected, or even do what it says it’s doing, which can be a tad frustrating at times. Sometimes it will outright refuse to generate an image and provide an error message. Other times it will say “Here’s your image!” but not actually generate any image. Ugh…
On the other hand I’ve seen DALL-E produce some amazing images, with wildly varying styles, demonstrating flexibility and sophistication. But only if prompted well it seems, which, turns out is a crucial skill when it comes to producing great GenAI images. Knowing some art history and having a solid design vocabulary do go a long way with DALL-E. Another thing to keep in mind with DALL-E is that it automatically does prompt enhancing in the background. This means that if you ask for “a watercolor painting of an owl in a barn” it will add extra words to spice up your prompt before actually running it. As a result, even simple prompts can generate lovely images.

Style referencing is possible with DALL-E, though I haven’t tried it yet. And it’s gotten much better at rendering text in images lately. Editing options are very basic, but effective, using a combination of an eraser and text prompting. And while DALL-E 3 was unable to do outpainting for quite some time after being released, it’s now quite capable of extending a 1:1 image to 16:9 without generating a completely different image.
Leonardo DiComplicado

This was the first GenAI tool that I found I could get my head around when it came to getting amazing results for specific styles and/or subject matter, even though on the surface it’s got a much more complicated UI than DALL-E. Part of the deal seemed to be an exchange of simplicity in exchange for specificity. It might take more time up-front, specifying a myriad of settings, but then it delivers something along the lines of what you’d expect. And if it doesn’t you can adjust the settings and try again. The drawback to this flexibility is that I find it either takes a lot of trial and error and time waiting for images to generate, or I get decent results quickly but only after getting to know the options that produce the kinds of images you’re looking for. But that up-front investment only gets you so far because the app is always adding new models and options, and so there’s an almost constant learning curve. In the time that I’ve been using it, it’s gotten more complicated while other tools have gotten easier.
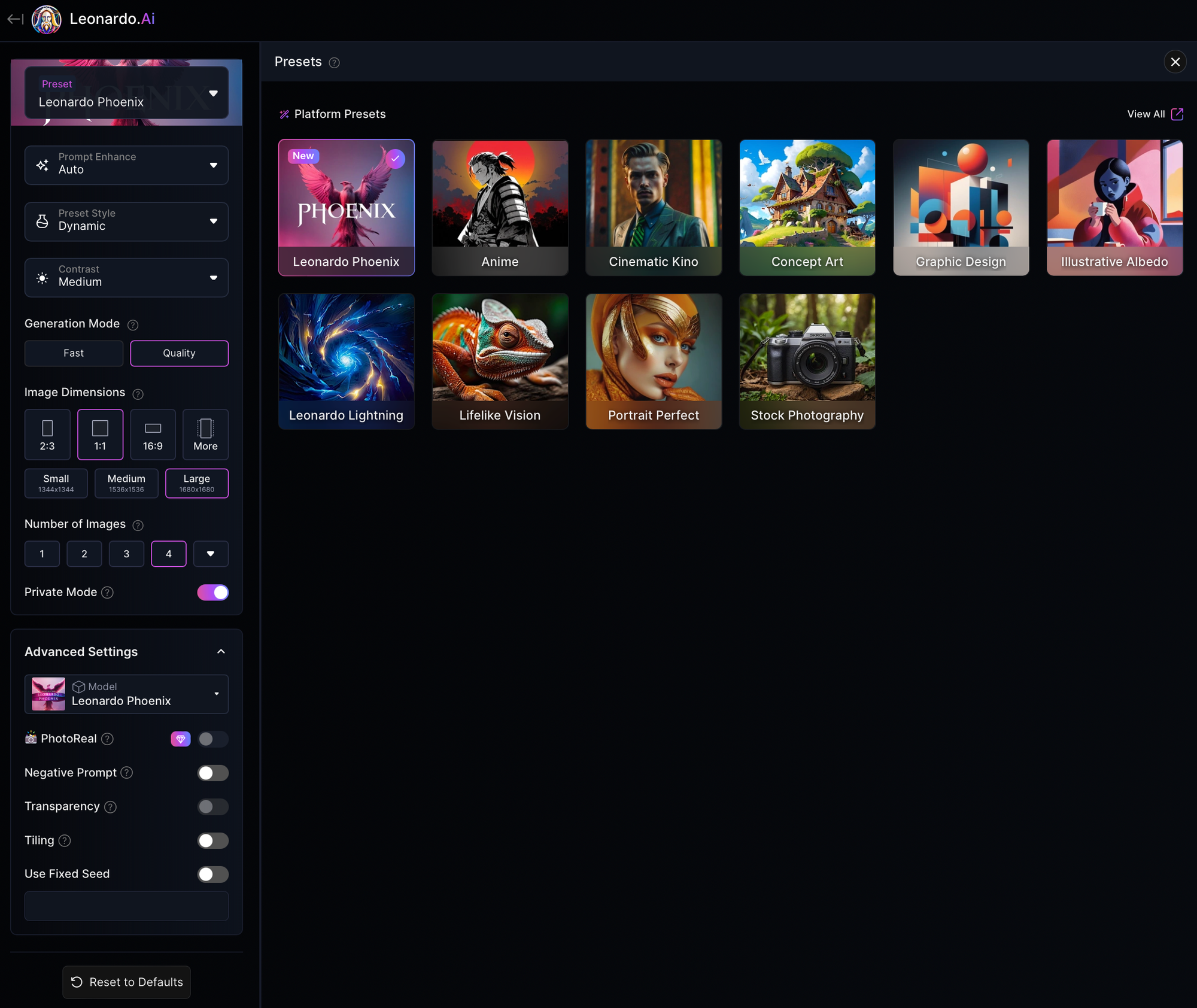
If you want bells and whistles, Leonardo is the best option. Besides basic image generation which requires adjusting a ton of individual settings, there are dedicated tools for upscaling, editing, and realtime generation (which is when you sketch a picture and the AI generates a corresponding image). These tools are all wrapped in their own interfaces and use different engines, so the whole thing kind of feels like it was bolted together vs being harmoniously implemented into a single thoughtfully crafted system. Side note, Canva recently acquired Leonardo Ai, the company, for a huge sum of money. Supposedly this purchase was purely strategic for Canva and they’ve promised no significant impacts to Leonardo, but only time will tell.

Style reference yes. There’s a UI for that and it’s pretty flexible once you get the hang of it. Creating your own LORAs is also possible, which means you can fine tune models using a larger number of reference images to achieve more consistency in your images, which is helpful for people looking to establish a consistent style such as a brand might want. Video is possible, but the clips are very short and it isn’t very good. They call it “Motion” if that’s any indication of its capabilities.
Stable Confusion

Stability AI has possibly been the single greatest contributor to generative AI image creation over the past couple years, by making its Stable Diffusion model available to other companies to use in their own tools. In fact, various flavours of their model are still accessible through other popular tools like Leonardo. If you see model names like SDXL 1.0, or Stable Diffusion 2.1, you know it’s powered by Stable Diffusion. At least part of the reason for this is because for a long time Stability AI didn’t have its own interface. Instead they made their models available to researchers, artists, and other developers through a combination of free and paid commercial licenses. Rather than working on developing a consumer-facing product, they focused on research and development of the actual models. But eventually this business model proved to be a problem: they ran out of money, had to force out their founder and CEO, lost many of their top developers (see Black Forest and the Flux1 story), and had to raise more money just to keep the lights on. During this chaotic phase (which all happened over the past 9 months or so) they released 2 completely different interfaces with different names, both powered by their most recent model: SD3 Ultra. One option is called Stable Assistant, which is web based. The other option is called Stable Artisan, which is only available on Discord. A subscription to one provides access to both, but only if you subscribe using a Discord login. Confusing? Yes. Practical, not at all.
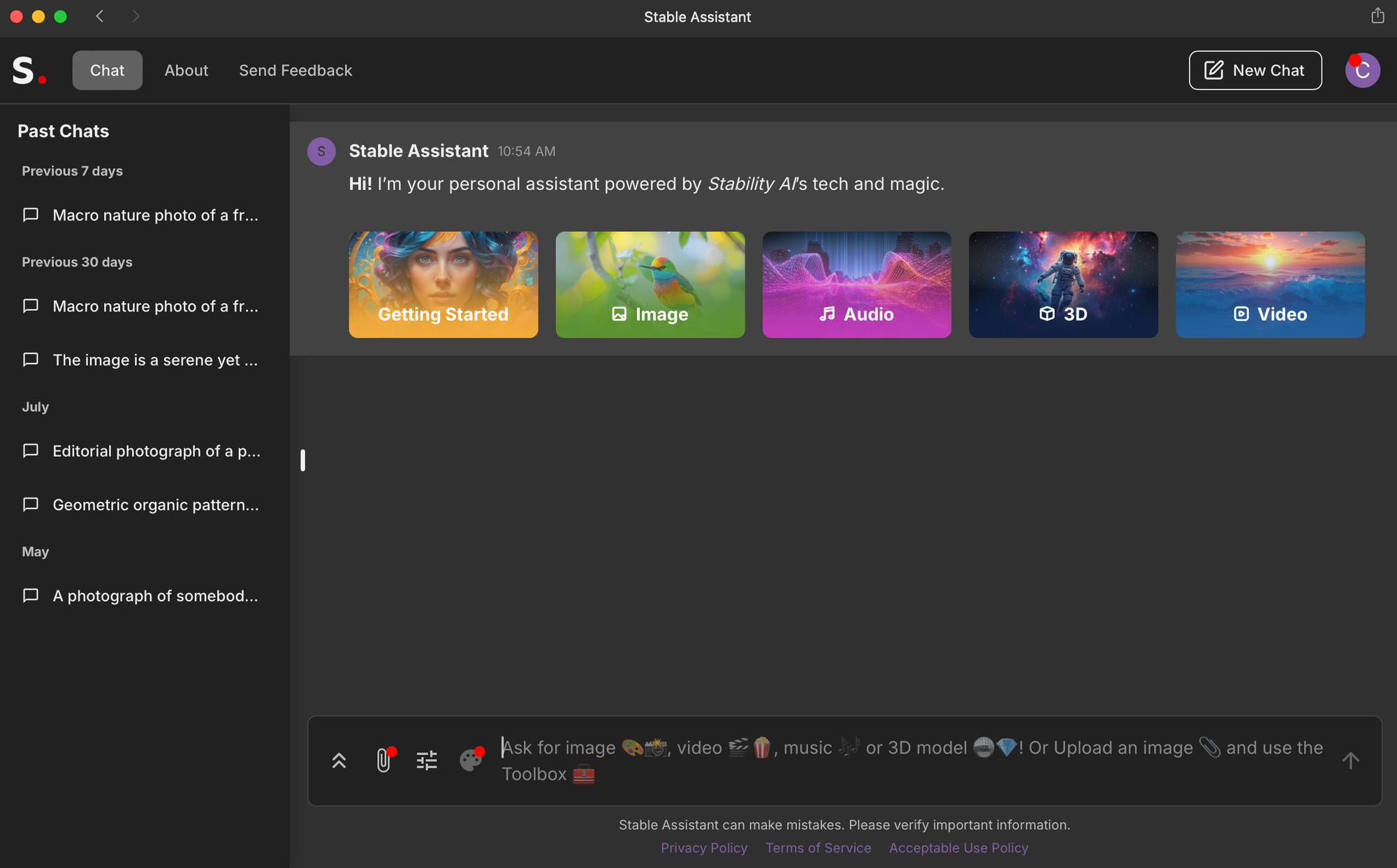
But how is Stable Diffusion for generating images? Pretty decent! SD3 is much better at rendering text than previous models, though it still isn’t perfect. Photo realism is pretty great, though maybe not the best. Illustration styles are dynamic and impressive. And the web interface is pretty easy to use, while being fairly basic in terms of editing tools.

I’m not going to get into the Stable Artisan option because it’s only accessible via the Stable Diffusion Discord server as a chatbot, and there’s no way to generate private images. Early on they promised that “private chatbot” capabilities (similar to Midjourney’s) would be available “in the coming weeks” but those weeks have turned into months and there’s been no update on that front as of my writing this.
Mighty Midjourney

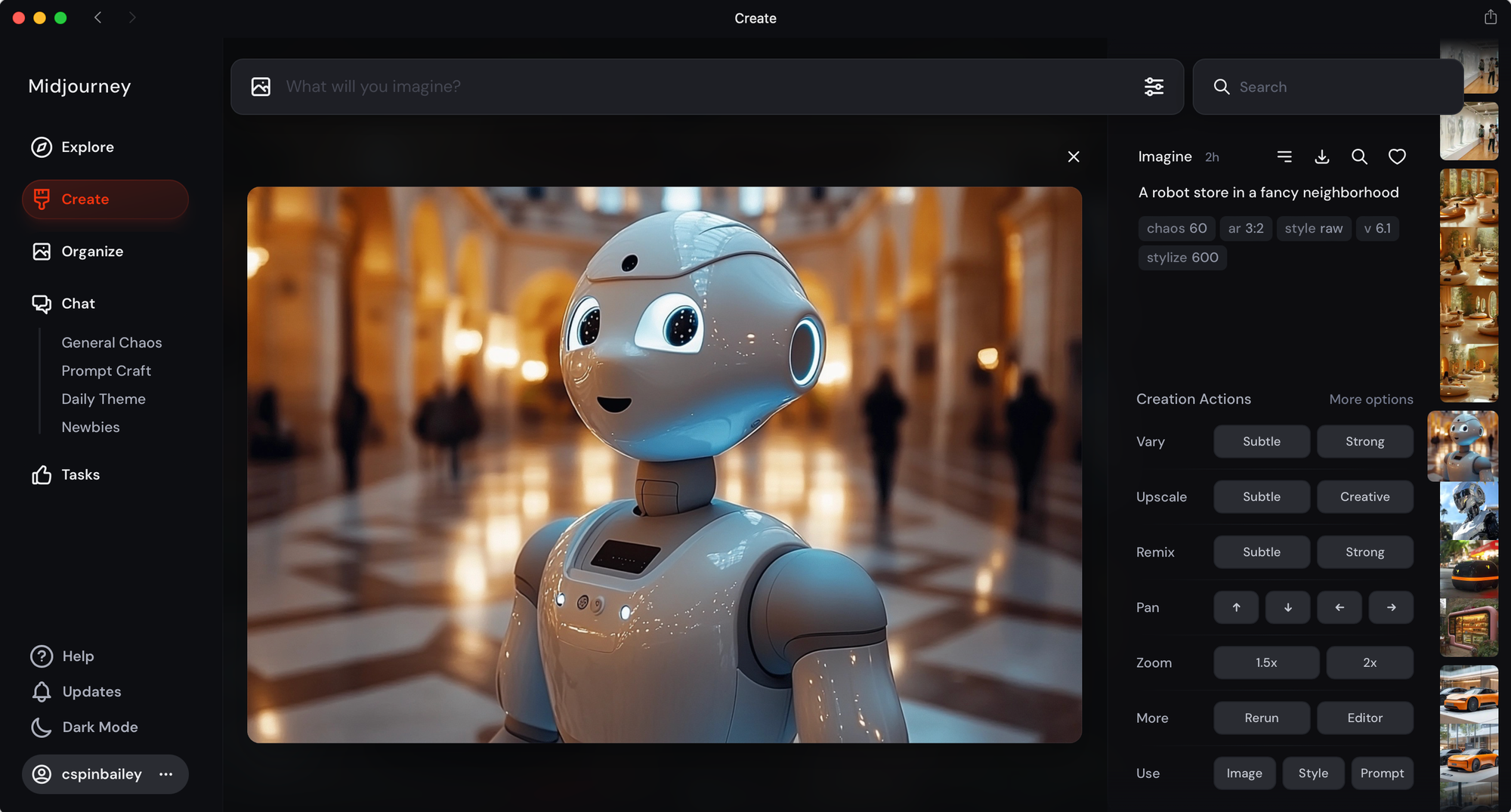
For a long time, relatively speaking, Midjourney was the most challenging of all the tools to even access. The barrier to entry seemed intentionally high, forbidding even. First, to generate images you could either use Discord, which is a chat platform mostly used by teenagers and video gamers, or you could use the Midjourney API and connect via an even more difficult and complicated tool called ComfyUI that you get off of GitHub. Add to that there is no free tier so you can’t try before you buy. It’s understandable why few people I know have used Midjourney. But the results! Oh my, just, beautiful. Seriously, they publish a monthly magazine and they put out a book featuring some of the best images generated on the platform.
So it took me awhile to get into Midjourney, as I had to figure out how to set up a Discord server, create private channels, invite the Midjourneybot to my server, and how to prompt it, all of which was a learning experience. Eventually I was rewarded with some pretty gorgeous images and I was glad I made the effort. Admittedly it took a lot more research and patience than the other tools, but there was also more documentation and numerous online resources to learn from. Compared to DALL-E’s simplicity, Midjourney can seem downright arcane. Prompting on Midjourney can be a bit like invoking AI voodoo magic with strange syntax and secret parameters. Practitioners must become one with the algorithms.

But then, earlier this summer the Midjourney team announced and launched a web-based UI, in alpha, and opened it to users that had generated over 100 images. It was a pretty bare-bones experience initially, and for a while I preferred the Discord UI, which by that point had become familiar to me. Since that initial launch though, the web tool has gotten much better. It has a pretty slick but simple UI, and it received an additional boost recently from a new image model (v6.1) that is of higher quality overall and handles text much better, making it my go-to tool at this point.
Considered but not covered
There are a few other tools that I haven’t spent a ton of time exploring, despite wanting to, like Ideogram and Civitai. They offer compelling features, and would even rank as the best options for specific features or capabilities, but those things haven’t been my priorities. Ideogram, for example, has the best overall text rendering capabilities, at least as far as accurate spelling is concerned. But Ideogram has also decided to limit some pretty key features, including private image generation and the ability to delete images, making them exclusive to the 2nd highest paid tier and up. This makes it a lot more expensive than the other tools. Civitai meanwhile, is the most “open” of all the options and has a ton of models and LORAs to work with , but it also has a much more NSFW vibe than all the others. The freedom to generate and post AI porn on Civitai means it’s a no-go for most professional work.
How they all stack up

I asked ChatGPT to help me build a comparison table, to provide an at-a-glance ranking of the four tools I’ve reviewed. As with all AI generated content, it required some feedback and adjustments, but I think the following table is a fair assessment of these tools.
| Feature/Capability | DALL-E | Leonardo | Stable Diffusion | Midjourney |
|---|---|---|---|---|
| Ease of Use | ★★★★☆ | ★★★★☆ | ★★★☆☆ | ★★★★★ |
| Image Quality | ★★★★☆ | ★★★★☆ | ★★★★☆ | ★★★★★ |
| Flexibility | ★★★★☆ | ★★★★☆ | ★★★★★ | ★★★★★ |
| Creativity | ★★★★☆ | ★★★★☆ | ★★★★☆ | ★★★★★ |
| Inpainting (Editing) | ✔️ | ✔️ | ✔️ | ✔️ |
| Outpainting (Zooming) | ✔️ | ✔️ | ✔️ | ✔️ |
| Character Reference | ✔️ | ✔️ | ✔️ | ✔️ |
| Image Reference | ✔️ | ✔️ | ✔️ | ✔️ |
| Style Reference | ✔️ | ✔️ | ✔️ | ✔️ |
| Text-to-Image | ✔️ | ✔️ | ✔️ | ✔️ |
| Custom Models | ✖️ | ✔️ | ✔️ | ✖️ |
| API Access | ✔️ | ✔️ | ✔️ | ✔️ |
| Community and Support | ★★★★☆ | ★★★★☆ | ★★★☆☆ | ★★★★★ |
| Collaboration | ★★★☆☆ | ★★★★★ | ★★★☆☆ | ★★★★☆ |
Wrap it up and take it to go

While most of my focus so far has been on basic image generation, something I haven’t really touched on yet is mobile compatibility. The ability to generate images from my iPhone has been a key differentiator when I want to explore in a more casual and playful way. I don’t always want to sit at a desk or have to pull out a laptop whenever I’m inspired to create an image. In fact, I often generate initial concept images while I’m relaxing on the couch, or having breakfast, or even while standing in the kitchen waiting for the kettle to boil. Sometimes inspiration strikes when I’m out in nature. The process of getting the right image can involve an extended exploration phase, where I generate a few images, let them sit for a bit, then come back and generate a few more. I also tend to bounce from tool to tool, trying the same or similar prompts in each to see which tool comes closest to achieving the desired result. Some of the tools, like Leonardo and DALL-E, have dedicated iOS apps, while others simply have a responsive website. Midjourney and Stability AI offer Discord’s decent mobile app as an option, but they also have decent web apps at this point (though the UX is degraded on mobile). I think this differentiator will matter less for some people and use cases, but it’s worth considering if you value spontaneity and freedom to create while away from your desk.
Where do we go from here?

There is currently a lot of uncertainty mixed with inevitability when it comes to the future of generative AI and image generation specifically, as a number of legal cases and technological threats have been issued in response to civil (and professional) unhappiness about the way most of the underlying models have been trained, and where compensation and consent are concerned. While there are certainly valid objections, and legalities and settlements are still to be determined, it’s also pretty clear that the genie is out of the bottle and there’s no going back. These are incredible tools and even artists who are currently objecting may one day see the utility, and adopt them into their creative process. Either way, I look forward to witnessing history as it plays out, and enjoying the spectacle, for all the audacity and bravery on display. The stakes are high, and change is inevitable. Best to keep enjoying it while we can.
Cover image made with Midjourney. Editing assistance provided by ChatGPT-4o.