Hearing Is Believing: Advances in AI Speech Tech

The sound of a person's voice is profoundly personal. It's as unique as a signature and can even be used to verify someone's identity. So it's both fascinating and disconcerting that recent AI advances in the realm of voice generation have gotten to the point where it's become almost impossible to tell the difference between a real human and an AI-generated voice. Over the past few months I've been experimenting with several AI voice technologies from the leading companies and the quality and versatility have been improving in leaps and bounds. Going from obviously robotic voices just six months ago, to hyper-realistic speech that responds with human-like emotion and nuance, these developments affect multiple aspects of society, from content creation and voice-acting, to misinformation campaigns and cybersecurity.
How AI Voice Technologies Work

Before diving into specific products, it helps to understand the basics of how modern AI voice technology works. Unlike older text-to-speech systems that pieced together pre-recorded sounds, today's AI voice models use neural networks trained on thousands of hours of human speech. These deep learning models analyze patterns in speech data, including tone, pitch, rhythm, and emotional inflection, to generate entirely new speech that convincingly mimics human vocal characteristics. And similar to how other generative AI systems never produce the same output twice, neither do these new voice engines.
Going one step further, the most advanced systems on the market combine large language models (similar to those powering chatbots like ChatGPT) with specialized speech models. This allows them to not just pronounce words correctly, but to understand the content and context of what they're saying, and adjust their delivery accordingly. This means they might pause for emphasis, raise their pitch for questions, or lower their volume for intimate moments. The uncanny valley of voice is here, and we're on the verge of crossing it.
Open Sesame

The other day I was trying out a new AI technology that's been getting some buzz for its amazingly life-like ability to speak like a human. Before actually releasing a product, Sesame AI launched a demo that lets you engage in a realtime conversation with its breakthrough tech using two different voice-bots. My initial impression after spending about a minute of chitchat was just "wow - impressive!" What was most striking about my conversation with Maya, one of the demo voices, was just how nuanced the intonation was, with pauses, dips and rises all relevant to what it was speaking about. If you've ever tried Advanced Voice mode in ChatGPT, it's comparable. The difference is that this is coming from a small lab, not a huge established company like OpenAI.
This week Sesame released the CSM (Conversational Speech Model) base model on GitHub and made it open-source, meaning anyone can download it and use it for free, provided you've got the infrastructure required to run it. They also set up a hosted Huggingface space where you can try it out for free and even clone your voice. Somewhat alarmingly you can have it say whatever outrageous things you want, because it doesn't have any guardrails in place, meaning there are no built-in safety limitations or content filters to prevent misuse or creation of potentially harmful content. Hopefully the engineers at Sesame are working on addressing that oversight.
Hume Drops an Octave

Prior to Sesame coming on the scene, the most impressive voice tech I had tried was created by another small AI lab called Hume. They recently launched Octave (which stands for “omni-capable text and voice engine”), and claim it's “the first LLM designed specifically for text-to-speech” and the first text-to-speech system that understands what it’s saying. Obviously the ability to have a voice adapt to the text it’s reading is incredibly compelling, but it’s basically what the Sesame technology is offering for free. One difference however, is that Hume’s model allows you to provide custom “acting instructions” similar to prompting a chatbot. The model then uses that prompt to guide the voice accordingly. It's pretty slick. Unfortunately it's also flakey.
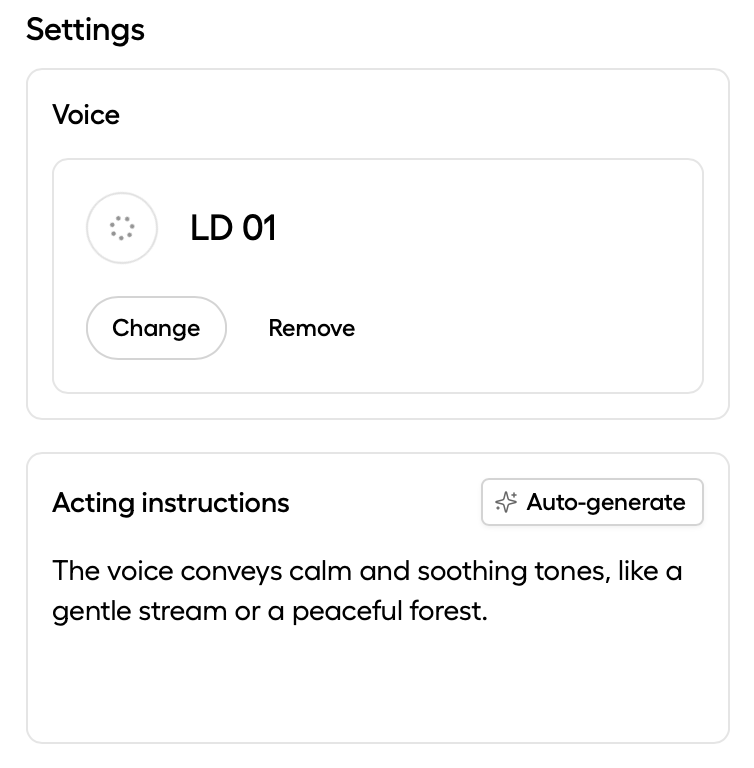
Technically Hume’s Octave was announced just one day before Sesame’s OSM model, but regardless Hume has already gone much further with productizing their technology, and the company has put more energy into releasing tools that content creators can leverage today by creating an account on their website. They’ve also put out APIs for developers who want to integrate Hume’s technology into applications like voice-powered chatbots or video games.
This Lab goes to 11

The original innovator in the “AI voice” space is ElevenLabs. They were the first to widely commercialize voice-cloning and dubbing tools for content creators way back in 2023, and quickly capitalized on the early buzz with an initial $2 million in investment capital. They used some of that money to license famous celebrity voices including James Dean and Deepak Chopra, and they’ve since expanded their library of voices to support numerous languages and offer a vast array of accents and vocal styles to choose from.
When I first tried using ElevenLabs several months ago, I was disappointed with the output. While the voices sounded like real people, they didn’t speak like real people. After a few sentences you could easily tell it was AI because the voices were essentially flat, lacking any variation in tone or expressiveness from one sentence to the next. There was no contextual awareness of the content, and no way to modify the voices, so even though there were hundreds to choose from, once you selected a voice every sentence sounded the same. After some initial experimentation I cancelled my subscription.
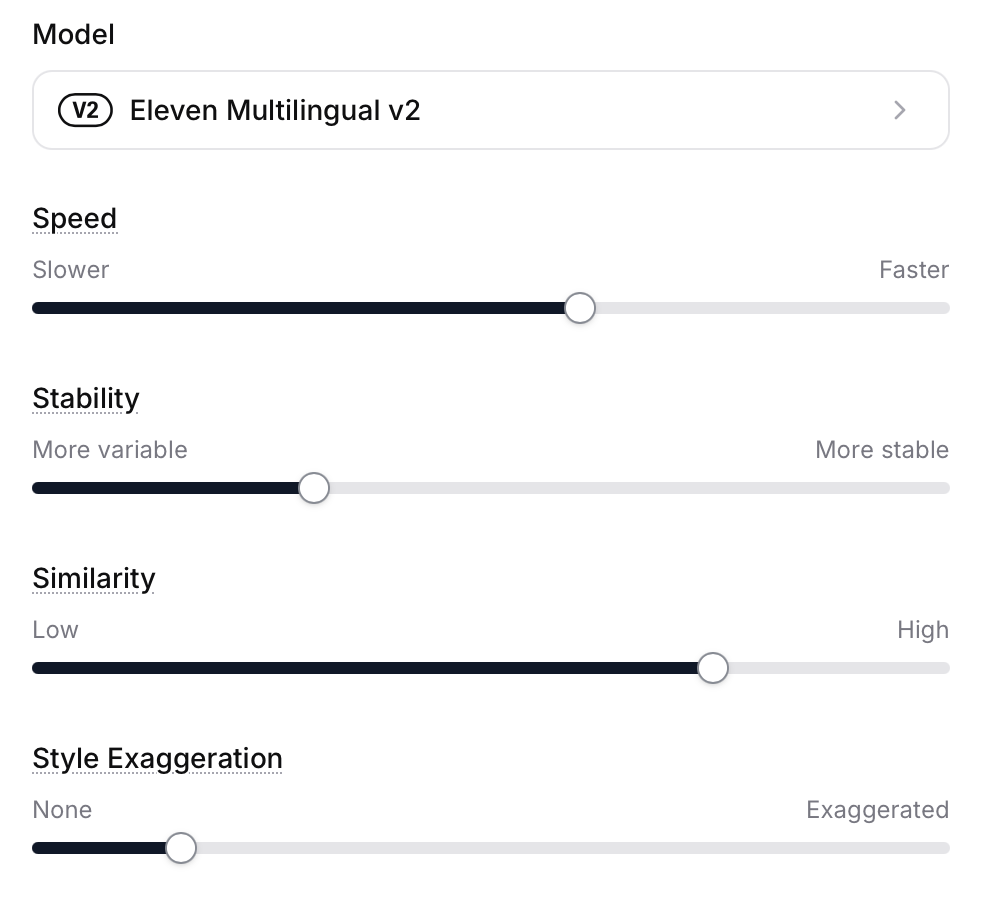
ElevenLabs has obviously been busy since then. They recently upgraded their text-to-speech tool to allow granular control over voices (including cloned voices, should you wish to digitize your own voice). You can now control the speed (voice pacing) which gives you a bit more control over the expressiveness of dialogue, but in practice it requires adjusting the slider and generating multiple times until it comes out just right. The Stability setting controls the expressive variety and emotional range of the voice, while the Similarity setting determines how much the voice deviates from the original default recordings. Style Exaggeration attempts to amplify the style of the original speaker but it’s a bit experimental and doesn’t always generate good results so the company actually recommends leaving it set to “none” at all times.
Sounds Like Trouble

While the power of voice is unquestionably compelling, and there are some very good use cases for this technology, whether it’s narrating a story or providing a chatbot with a voice, a negative public perception of synthetic voices has been building, with major ethical issues related to voice cloning and the potential for fraud and disinformation.
The ability to clone someone's voice with as little as a 30 second sample creates an all-too-easy opportunity for criminals intent on defrauding banks, corporations, and even the general public. In 2020, attackers cloned a company director's voice, convincing a bank manager to transfer $35 million to their account. Several months ago scammers replicated a man's son's voice, claiming he was in a serious accident and needed $25,000 for bail, which the victim provided. And during the run-up to the 2024 US federal election a political consultant used AI to clone President Joe Biden's voice in robocalls, urging New Hampshire voters to abstain from voting in the Democratic primary. This led to a $6 million fine by the Federal Communications Commission.
Beyond the criminal concerns, some people’s jobs are now at risk. concerns over AI's impact on voice acting have led to labor strikes. Notably, in July 2024, SAG-AFTRA initiated a strike against major video game companies. The union sought to secure protections against the use of AI to replicate actors' voices and performances without consent or fair compensation. As of March 2025 negotiations are ongoing, with the union stating that they are still "frustratingly far apart" from reaching an agreement on AI protections within the industry. There have already been instances of video game studios replacing voice actors with AI.
Listen Before You Leap

Whether you believe AI voice technology is a blessing or a curse to humanity, like the many other forms of generative AI that have been unleashed on society over the past few years, it is clearly here to stay. The debate is not about whether or not it should be allowed to exist, but how can it be contained and controlled in a way that allows for creative expression without being used for malicious purposes. How can we as a society leverage this technology for good and simultaneously protect ourselves from harm? Now that there are more AI labs releasing ever more convincing voices into the world, how will we be able to know if we can trust what we’re hearing? ElevenLabs offers a tool called AI Speech Classifier to let people upload an audio sample to determine if it was created by their technology. Meta has AudioSeal and Google developed SynthID, both watermarking technologies for AI-generated content. These detection methods are a good start, but the onus is on the audience to use them (and even to be aware of them).
And while several laws have been passed in the US to protect people from having their voices cloned without consent and the FCC has expressed concerns about the misuse of AI-enabled voice cloning, there are currently no frameworks in place to prevent these potential harms from happening. At this point we are at the mercy of the AI labs to build guardrails into their products and hope that they work. Unfortunately any sense of complete protection from vocal deception is unlikely at this point. Similar to AI-generated images, we’re ultimately left to our own judgement to determine if we should trust what we’re hearing, and that means that many people are going to be deceived. With that in mind, next time you get a strange feeling while listening to a podcast or audiobook, at least now you'll know why.
All images except product screenshots were generated with Midjourney v6.1
Audio version of this post generated with ElevenLabs' Studio.